LSP2 - ERC725Y JSON Schema
Our JavaScript library erc725.js makes it easy to read + write data encoded according to the LSP2 Schema without manually going through all the encoding complexity.
Goal: Introduces a JSON schema for ERC725Y data keys
The LUKSO Standard Proposal 2, or LSP2, introduces a new way to structure, store and represent data stored in smart contracts through the ERC725Y JSON Schema. This innovative approach allows for the storage of structured data directly on-chain, utilizing the flexibility and accessibility of JSON formatting for ERC725Y data keys. Imagine being able to store your blockchain identity's profile information, preferences, or even configuration settings in a standardized, easily retrievable format. That's what LSP2 enables.
By adopting the ERC725Y JSON Schema, developers can define clear, consistent data structures for their applications, enhancing interoperability and ease of integration across the LUKSO ecosystem. This structured approach not only simplifies data management but also paves the way for more complex and user-friendly decentralized applications. With LSP2, the potential for creating rich, interactive, and personalized user experiences on the blockchain becomes a reality, opening up a world of possibilities for developers and users alike.
Introduction
The storage of a smart contract consists of multiple storage slots. These slots are referenced by a slot number (as an integer) starting from slot 0. Each piece of data (= contract state) in a smart contract is stored as raw bytes under a specific storage slot.
In summary, smart contracts understand only two languages: bytes and uint256. Take the following key-value pair, for instance. It is not easy to infer the meaning of these data keys by reading them as bytes.
(key) => (value)
0xdeba1e292f8ba88238e10ab3c7f88bd4be4fac56cad5194b6ecceaf653468af1 => 0x4d7920546f6b656e20322e30
Using slot numbers and raw bytes makes the contract storage very hard to handle. ERC725Y solves part of the problem through a more flexible storage layout, where data is addressed via bytes32 keys. However, with such low-level languages, it is difficult for humans to understand the data in the storage.
The main problem around smart contract storage also arises when data is stored differently, depending on individual use cases and application needs. No standard schema defines "what the data stored under a specific data key represents".
These two issues make it very hard for smart contracts to interact with each other and for external services to interact with contracts' storage.
What does this standard represent?
The LSP2 Standard aims to offer a better abstraction on top of the storage of a smart contract.
This standard introduces a JSON schema that enables to represent the storage of a smart contract through more understandable data keys. It makes the data stored in a smart contract more organized.

By introducing a schema, we can represent contract storage in the same way across contracts in the network. Everyone has a unified view of the data stored between smart contracts. Developers can quickly parse data, and contracts or interfaces can read or write data from or to the contract storage in the same manner. The standardization makes smart contracts more interoperable with each other.
Specification
LSP2 introduces new ways to encode data, depending on its type. From single to multiple entries (like arrays or maps).
A data key in the contract storage can be defined as a JSON object with properties that describe the key. The schema includes information about the data key itself, as well as its value to explain what this data represents.
{
"name": "LSP4TokenName",
"key": "0xdeba1e292f8ba88238e10ab3c7f88bd4be4fac56cad5194b6ecceaf653468af1",
"keyType": "Singleton",
"valueType": "string",
"valueContent": "String"
}
Below are descriptions of what each properties in the JSON schema represent.
| Property in JSON schema | Explanation |
|---|---|
data key name | Describe what kind of metadata value is stored under this data key in a human readable way. |
data key itself | The bytes32 hex value used when calling setData or setDataBatch on the smart contract. |
keyType | Define if the information stored under this data key is a single entry (Singleton), a list of items (Array), or map to a specific field like an address or unique identifier (Mapping and MappingWithGrouping). |
valueType | Describe the low level type to be used to encode or decode the data. |
valueContent | Describe how to interpret the data being fetched (is it some text? is it some URL? is it an address? is it a JSON object?) |
Data Key Types
A Data Key Type defines HOW a 32 bytes data key is constructed, representing how a particular data key type is described in 32 bytes. For example, Singleton data keys are simple keccak256 hashes of the key name string. Other Data Key Types are constructed of slices of hashes to group different key name parts or define array element keys.
The LSP2 Standard defines several data key types:
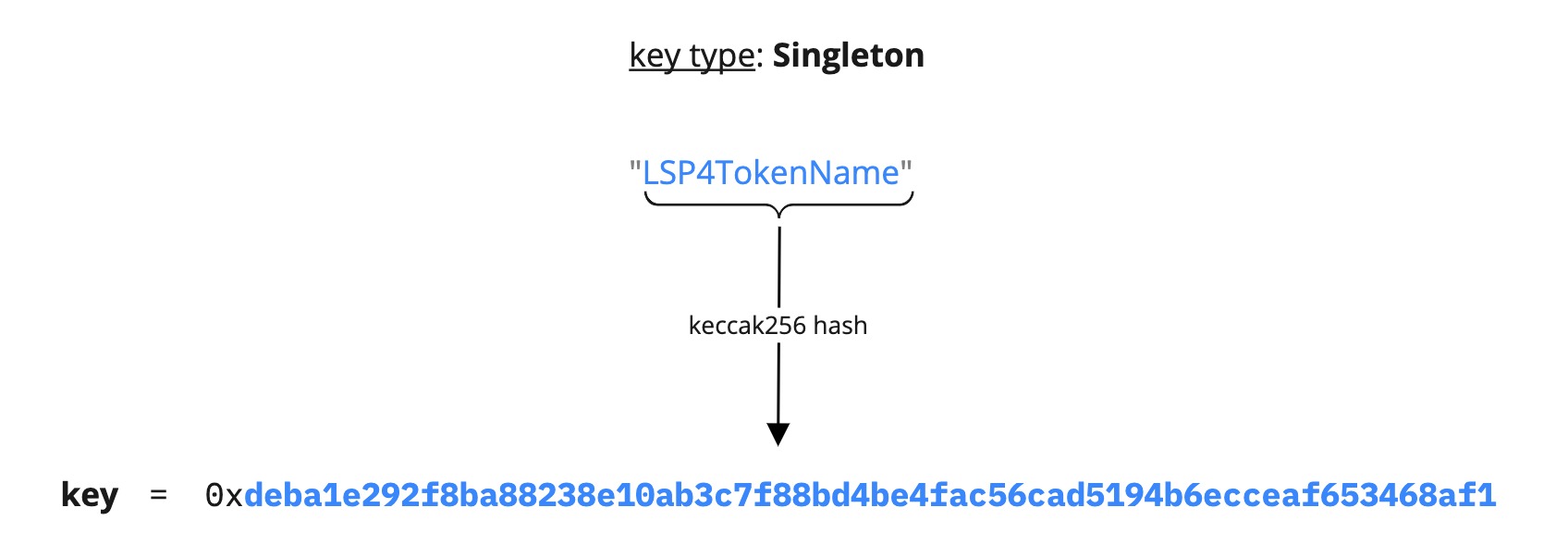
Singleton
A Singleton data key is helpful to store a unique single value under a single data key.
Below is an example of a Singleton data key.
{
"name": "LSP4TokenName",
"key": "0xdeba1e292f8ba88238e10ab3c7f88bd4be4fac56cad5194b6ecceaf653468af1",
"keyType": "Singleton",
"valueType": "string",
"valueContent": "String"
}
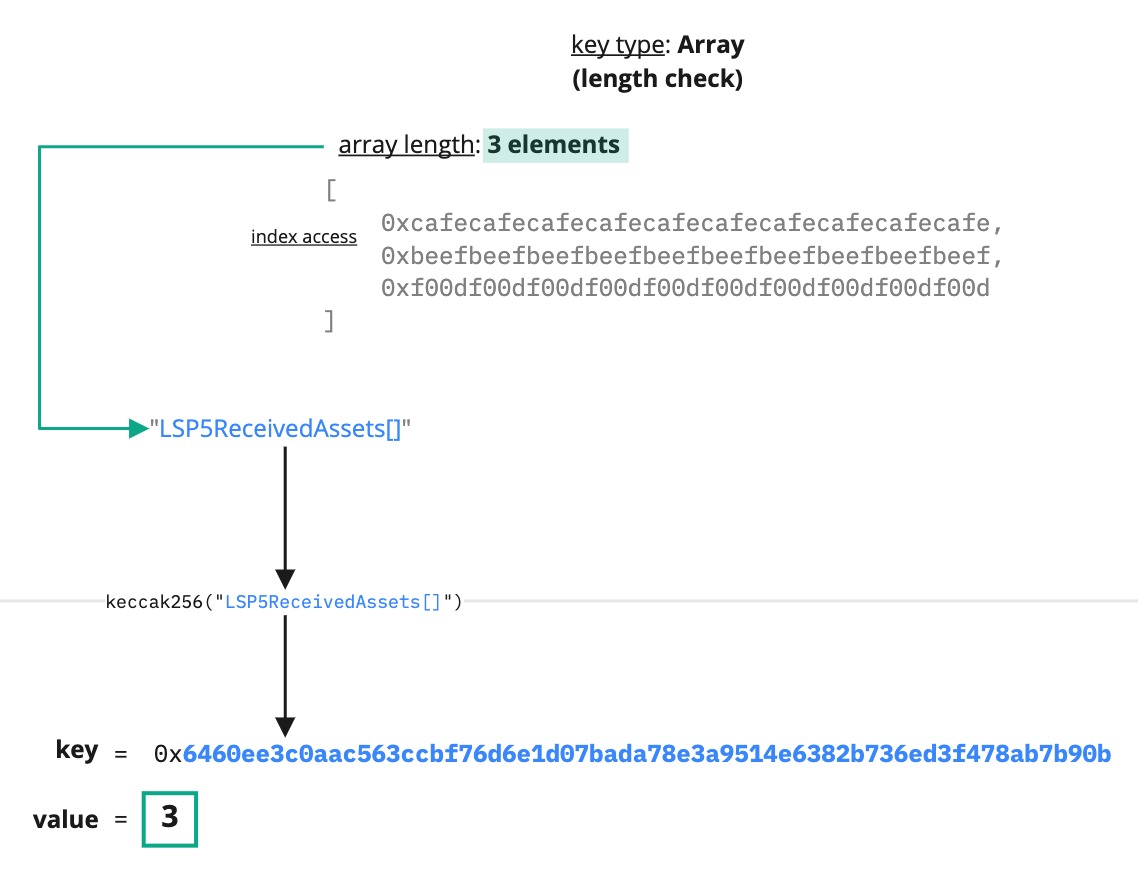
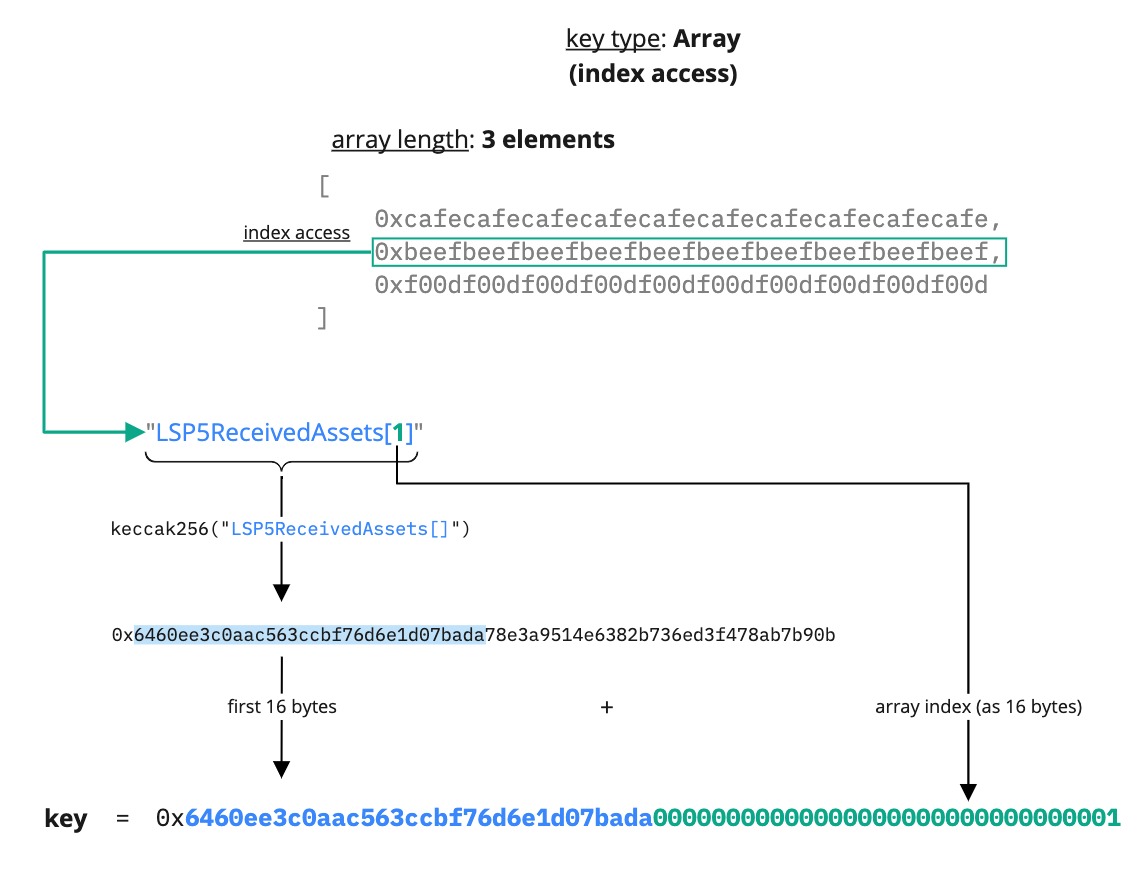
Array
Developers can use a data key of the type Array to store a list of elements of the same data type. They are accessed by an index that defines their position within it.
The Array elements are arranged systematically, in the order they are added or removed to or from it.
The main properties of the LSP2 Array data key type are:
- ordering matters ❗
- duplicates are permitted ✅
A data key type Array can be useful when there is the need to store a large group of similar data items under the same data key. For instance, a list of tokens or NFTs that an address has received. Below is an example of an Array data key:
{
"name": "LSP5ReceivedAssets[]",
"key": "0x6460ee3c0aac563ccbf76d6e1d07bada78e3a9514e6382b736ed3f478ab7b90b",
"keyType": "Array",
"valueType": "address",
"valueContent": "Address"
}
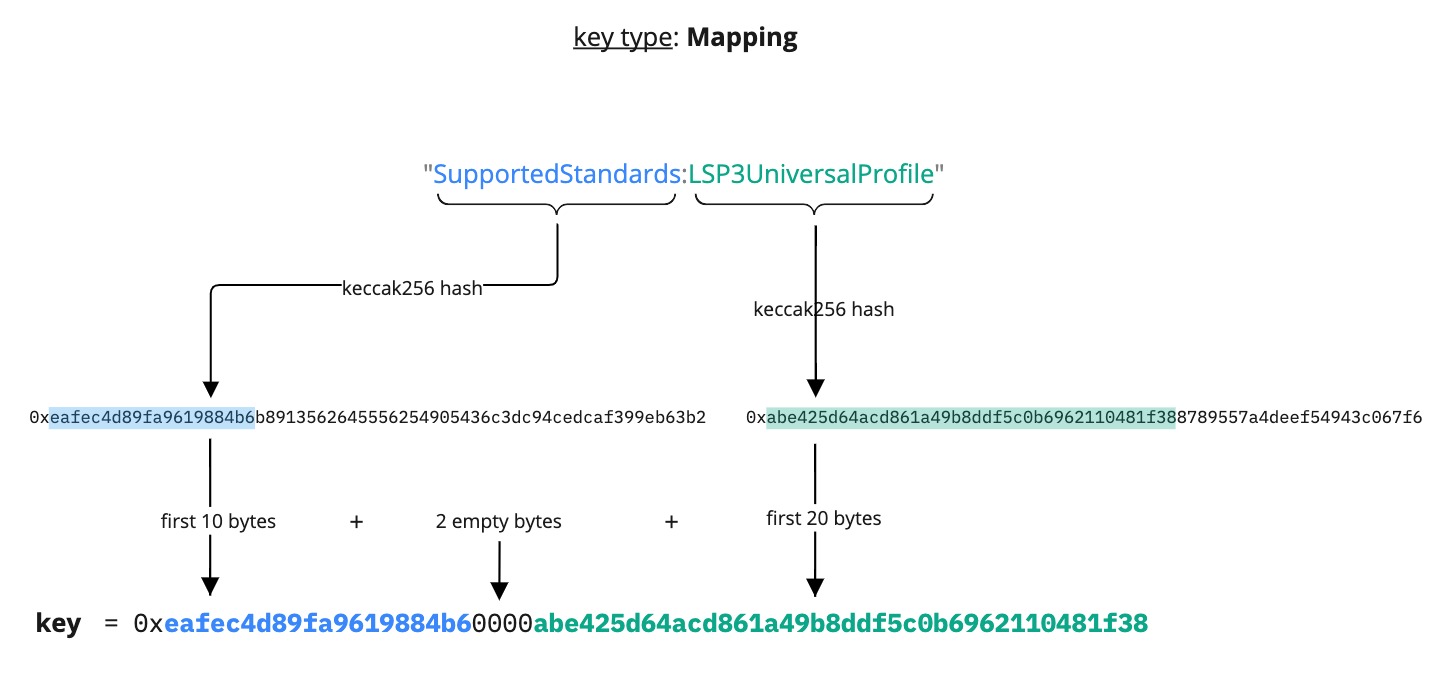
Mapping
The Mapping data key type is similar to the concept of lookup tables. It can be used to map data that have a shared significance (such as items derived from a common ancestor), and search or query specific elements efficiently.
The main properties of the LSP2 Mapping data key type are:
- ordering does not matter ✅
- duplicates are not permitted ❌
The data being mapped can be words that have a specific meaning for the protocol or application implementation, or underlying data types (= <mixed type>) like address, bytesN, uintN, etc. For <mixed type>, all the data types are left padded. If the type is larger than 20 bytes, the second part of the key is:
- left-cut for
uint<M>,int<M>andbool - right cut for
bytes<M>andaddress
Below are some examples of the Mapping key type.
- mapping to words:
SupportedStandards:LSP3Profile,SupportedStandards:LSP4DigitalAsset,SupportedStandards:LSP{N}{StandardName}, etc... - mapping to
<mixed type>, like anaddress:LSP5ReceivedAssetsMap:<address> - mapping to
<mixed type>, like abytes32:LSP8MetadataAddress:<bytes32>
Example 1: Mapping as FirstWord:SecondWord
{
"name": "SupportedStandards:LSP3Profile",
"key": "0xeafec4d89fa9619884b600005ef83ad9559033e6e941db7d7c495acdce616347",
"keyType": "Mapping",
"valueType": "bytes4",
"valueContent": "0xabe425d6"
}
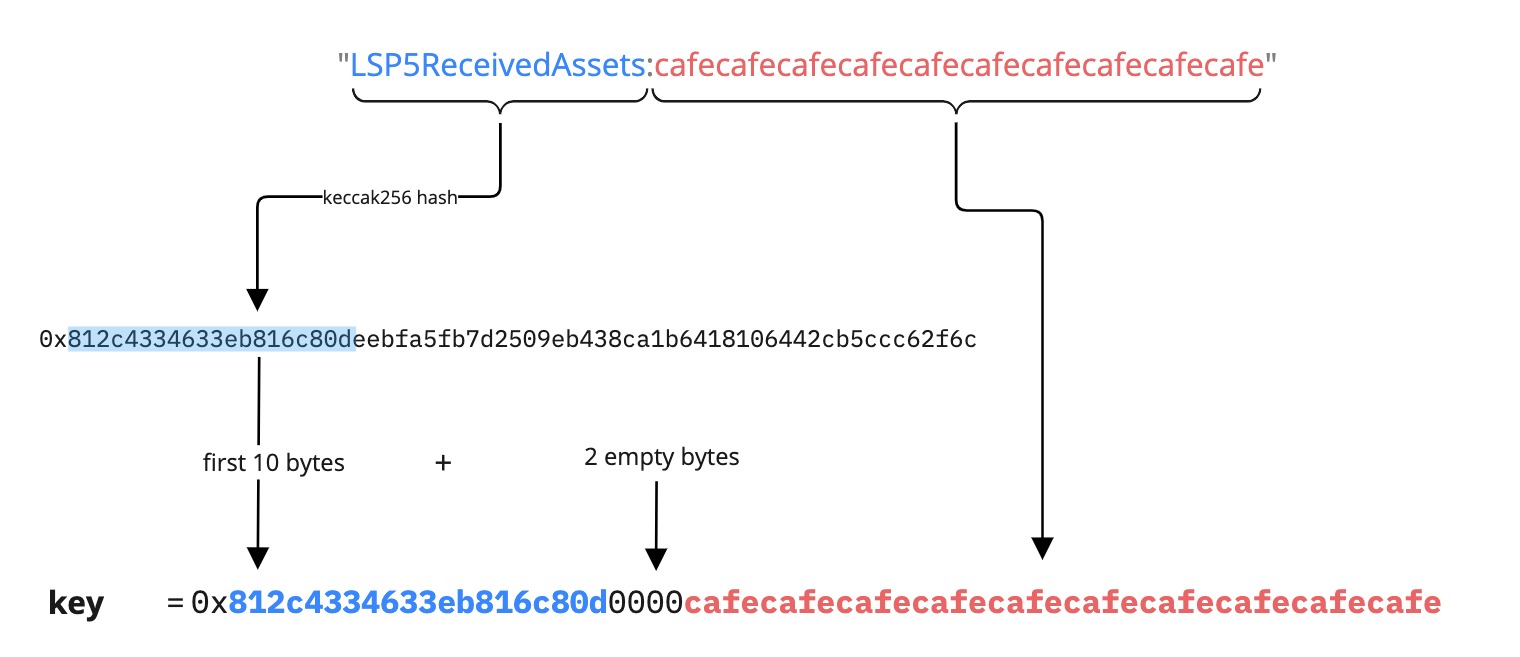
Example 2: Mapping as FirstWord:<address> (<mixed type>)
address value = 0xcafecafecafecafecafecafecafecafecafecafe
{
"name": "LSP5ReceivedAssetsMap:<address>",
"key": "0x812c4334633eb816c80d0000cafecafecafecafecafecafecafecafecafecafe",
"keyType": "Mapping",
"valueType": "(bytes4,uint128)",
"valueContent": "(Bytes4,Number)"
}
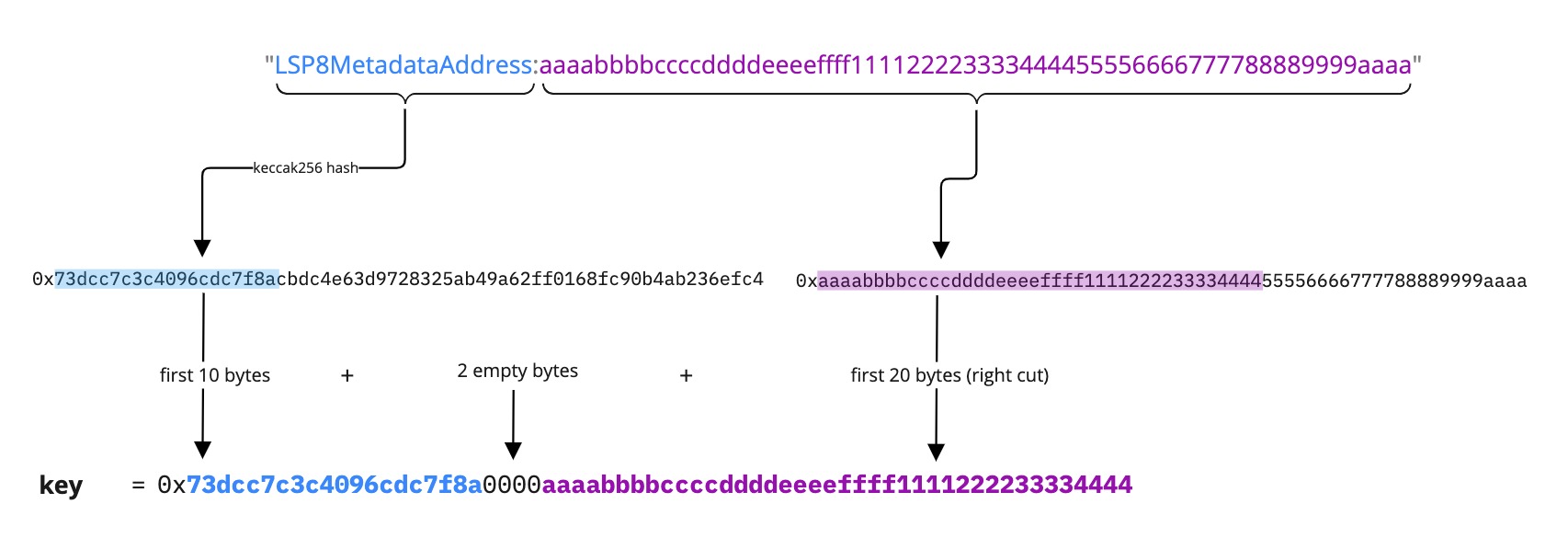
Example 3: Mapping as FirstWord:<bytes32> (<mixed type>)
bytes32 value = 0xaaaabbbbccccddddeeeeffff111122223333444455556666777788889999aaaa.
The bytes32 value is right-cut.
{
"name": "LSP8MetadataAddress:<bytes32>",
"key": "0x73dcc7c3c4096cdc7f8a0000aaaabbbbccccddddeeeeffff1111222233334444",
"keyType": "Mapping",
"valueType": "Mixed",
"valueContent": "Mixed"
}
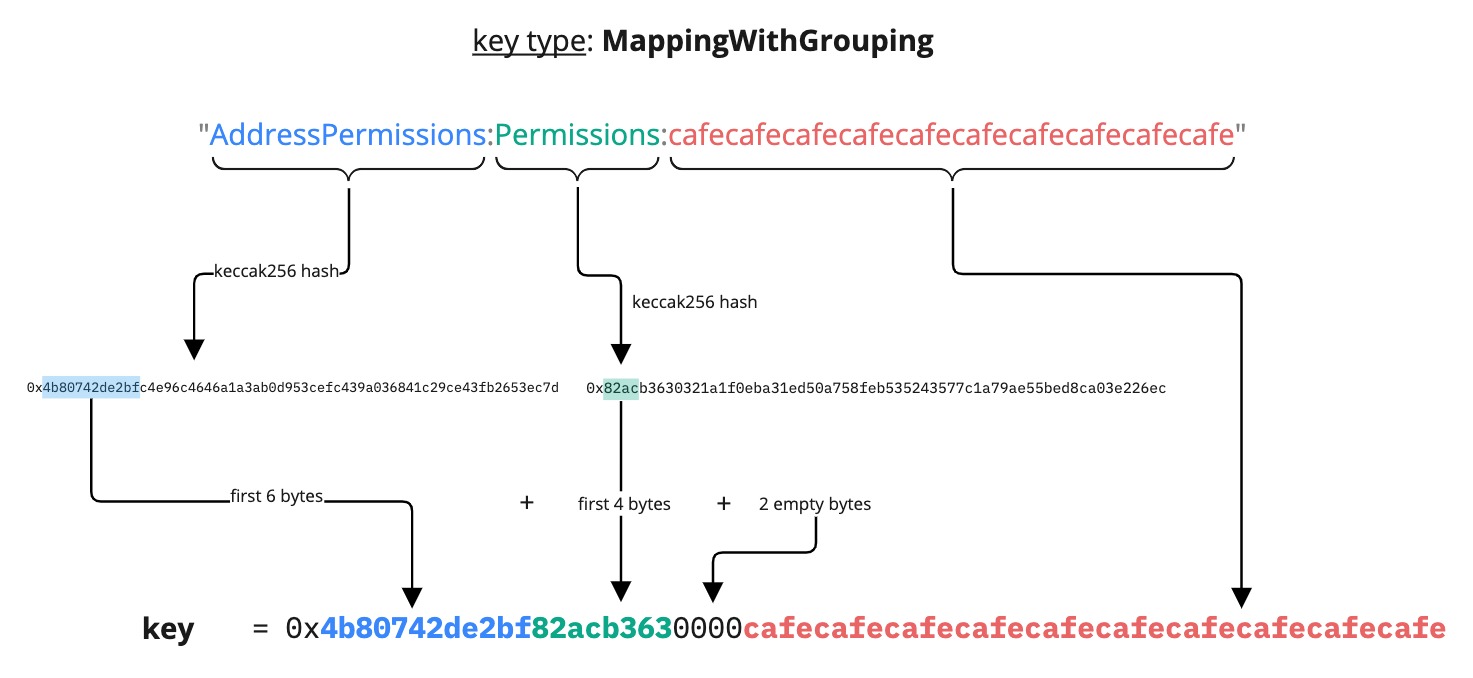
MappingWithGrouping
<firstWordHash>:<secondWordHash>:<bytes2(0)>:<thirdWordHash>
You must take into consideration the fact that if you choose the same value to hash for firstWord and thirdWord there is a 0.0000000233% chance that two random values for the secondWord will result in the same data key.
A data key of type MappingWithGrouping is similar to the Mapping data key type, except that sub-types can be added to the main mapping data key.
For instance, it can be used to differentiate various types from the primary mapping data key, like different types of permissions (see LSP6 - Key Manager).
Below is an example of a MappingWithGrouping data key:
{
"name": "AddressPermissions:Permissions:<address>",
"key": "0x4b80742de2bf82acb3630000<address>",
"keyType": "MappingWithGrouping",
"valueType": "bytes32",
"valueContent": "BitArray"
},
Solidity Example
Whenever you want to generate a data key of keyType MappingWithGrouping:
bytes32 dataKey = bytes32(
bytes.concat(
bytes6(keccak256(bytes(firstWord))),
bytes4(keccak256(bytes(secondWord))),
bytes2(0),
bytes20(keccak256(bytes(thirdWord)))
)
);
valueType encoding
Watch our following video for an overview of how static types (uintM, bytesN, bool), bytes and string are encoded in the ERC725Y storage of a smart contract using the LSP2 standard.
LSP2 differs in terms of how data is encoded depending on its type. As a basic summary, LSP2 and the ABI encoding specification can be compared as follow:
Differences:
- static types (types that have a fixed size like
uintM,bytesNandbool) are encoded as they are without any padding to make a 32 bytes long word. bytesandstringare also encoded as they are as arbitrary bytes, without any 32 bytes words for the offset or the data length.
Similarities
- any array types (e.g:
uintM[],bytesN[],bool[], etc...) in LSP2 are ABI encoded the same way as the ABI specification.
Below is a table that describe the LSP2 encoding format for valueTypes.
valueType | Encoding | Example |
|---|---|---|
bool | 0x01 or 0x00 | true --> 0x01 / false --> 0x00 |
string | as utf8 hex bytes without padding ❌ | "Hello" --> 0x48656c6c6f |
address | as a 20 bytes long address | 0x388C818CA8B9251b393131C08a736A67ccB19297 |
uint256 | as a hex value 32 bytes long left padded with zeros to fill 32 bytes | number 5 --> 0x0000000000000000000000000000000000000000000000000000000000000005 |
uintN (where N is a multiple of 8 bits in the range8 > N > 256) | as a hex value M bits long left padded with zeros to fill M bytes | number 5 as uint32 --> 0x00000005 |
bytes32 | as a hex value 32 bytes long right padded to fill 32 bytes | 0xca5ebeeff00dca11ab1efe6701df563bc1add009076ded6bcf4c6f771f2e3436 |
bytes4 | as a hex value 4 bytes long right padded to fill 4 bytes | 0xcafecafe |
bytesN (from 1 to 32) | as a hex value N bytes long right padded to fill N bytes | |
bytes | as hex bytes of any length without padding ❌ | 0xcafecafecafecafecafecafecafecafe... |
valueContent encoding
VerifiableURI
A VerifiableURI as defined by the LSP2 - ERC725Y JSON Schema is a type of encoding that allows anyone to verify that the content at the URI hasn't been tampered with.
It contains both a verification hash and the URI where the data can be found. The encoding format is:
| Bytes | Length | Description |
|---|---|---|
0x0000 | 2 bytes | Header — 0x0000 indicates a VerifiableURI |
| Storage options: - 6f357c6a (off-chain) - 8019f9b1 (on-chain) | 4 bytes | Verification method: first 4 bytes of the keccak256 hash of the following words: - "keccak256('utf8')" = bytes4(keccak256('keccak256(utf8)')), or - "keccak256(bytes)" = bytes4(keccak256('keccak256(bytes)')) |
0020 | 2 bytes | Hash length — 32 bytes in hex |
<32 bytes> | 32 bytes | keccak256 hash of the JSON content |
<url bytes> | variable | UTF-8 encoded URI (e.g., ipfs://<ipfs-cid> or data:...) |
A common mistake is to omit the 0020 (hash length) bytes from the VerifiableURI header. The full header for keccak256(utf8) is 0x00006f357c6a0020, not just 0x00006f357c6a. Missing the 0020 will make the data unreadable by clients.
For off-chain storage on IPFS (where the JSON file or image is uploaded to IPFS), the verification method is keccak256(utf8) with method ID 6f357c6a.
The encoded data MUST have the following header:
0x00006f357c6a0020...
For on-chain storage in base64 (where the JSON file or image is embedded directly in the URI as data:application/json;base64,...), the verification method is to keccak256(bytes) with method ID 8019f9b1.
The encoded data MUST have the following header:
0x00008019f9b10020...